Transflower
Probabilistic autoregressive dance generation with multimodal attention
Abstract
Dance requires skillful composition of complex movements that follow rhythmic, tonal and timbral features of music. Formally, generating dance conditioned on a piece of music can be expressed as a problem of modelling a high-dimensional continuous motion signal, conditioned on an audio signal. In this work we make two contributions to tackle this problem. First, we present a novel probabilistic autoregressive architecture that models the distribution over future poses with a normalizing flow conditioned on previous poses as well as music context, using a multimodal transformer encoder. Second, we introduce the currently largest 3D dance-motion dataset, obtained with a variety of motion-capture technologies, and including both professional and casual dancers. Using this dataset, we compare our new model against two baselines, via objective metrics and a user study, and show that both the ability to model a probability distribution, as well as being able to attend over a large motion and music context are necessary to produce interesting, diverse, and realistic dance that matches the music.
Generated dance samples
Samples in NeosVR
These samples are rendered in NeosVR using a tool to work with motion data in Neos. NeosVR is a social VR platform which means these dances can be used as part of multiplayer VR experiences. NeosVR applies a small amount of smoothing to the motion.
Transflower fine tuned samples
Next we show some samples of the raw generated motions. Note that in these videos the seed is all the same (fixed to one of the casual dancing seeds).
Transflower samples
You can see a few more samples in this playlist
Architecture
The architecture consists of a full-attention transformer encoder which encodes the multimodal context, and conditions a normalizing flow generator which models a probability distribution over future motions.
Pretrained models
These are the trained checkpoints for the transflower model in the code.
Trained transflower (other checkpoint)
Trained transflower fine tuned
We are working on training models on the full dataset, and we will release those too as sonn as they are ready.
Baselines
Dance dataset
We are compiling the dataset, which comprises several sources, and will release it soon.
User study
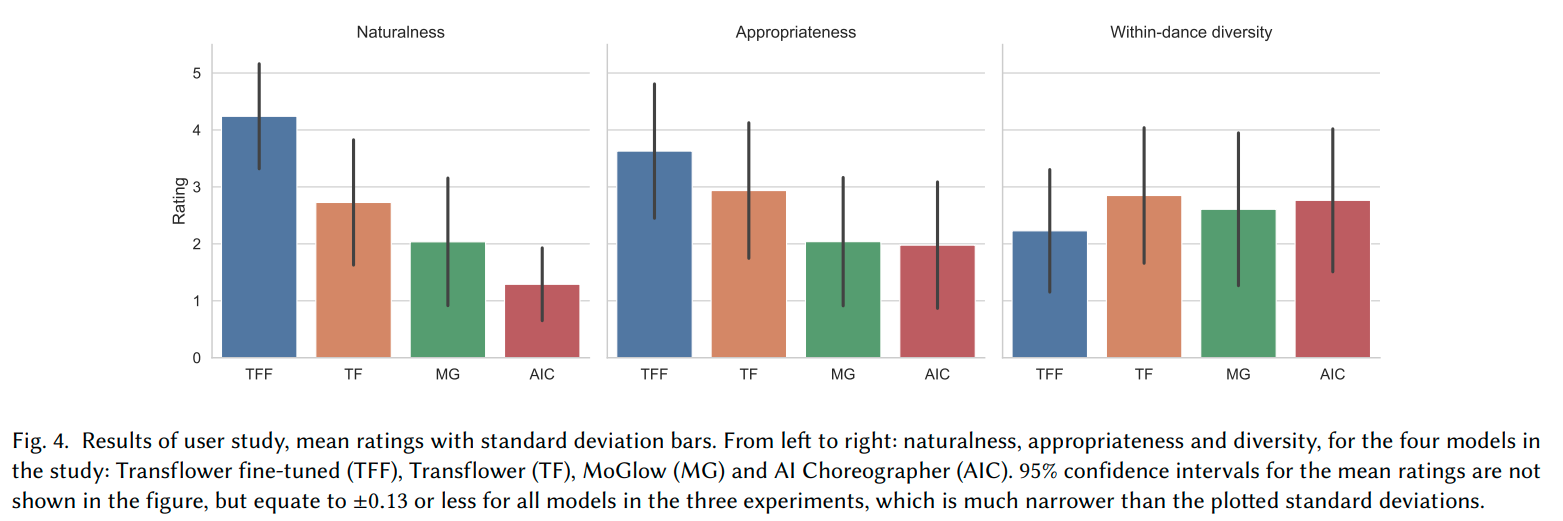
We performed a user study in which we asked participants to rate Transflower and the two baselines (AI Choreographer and MoGloW trained on the same data), in terms of naturalness, appropriateness to the music, and within-song diversity. The results show Transflower ranks, in average, higher than the two other baselines in all these dimensions. Furthermore fine-tuning increases naturalness and appropriateness, at only a modest decrease in diversity. See the paper for full details.
BibTex
To cite our work, you can use the following BibTex reference
@article{vallepérez2021transflower,
title={Transflower: probabilistic autoregressive dance generation with multimodal attention},
author={Guillermo Valle-Pérez and Gustav Eje Henter and Jonas Beskow and André Holzapfel and Pierre-Yves Oudeyer and Simon Alexanderson},
year={2021},
eprint={2106.13871},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
Acknowledgements
I (Guillermo) would like to thank lox9973 for his invaluable help in getting the VR dance data, both by making the mocap recording tool, and for finding dancers to participate. I’d also like to thank Konata and Max for being the first participants to donate data to the project. Thank you for beliving in it:) Thank you also to the coathors in the paper without whom this idea wouldn’t have happened, and to the friends supporting me during this project including Shin, lox, Kazumi, Choco, Sirkitree, among others. Finally, I’d like to thank Idris for the compute resources in Jean Zay, and the Google cloud research credits programs (including TRC) for their support. Both of these also made the project possible!